 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
A Brief Introduction To The Computer History Model
Brian D. Carrier
January 21, 2008
Abstract
This article describes the Computer History Model, which was a result of my PhD research at CERIAS. The Computer History Model is a mathematical way to represent what occurs in a computer and can be used to describe the digital forensics process. The dissertation is full of formulas and theory, but this article is a high-level overview of the model and describes how it can be applied to practical issues. It does not assume any formal computer science knowledge.
Motivation
Since the first Digital Forensic Research Workshop (DFRWS) in 2000, there has been talk about developing a framework or process model for digital forensics. Many have been proposed over the years (including a couple by myself) with little or no impact because the reality is that there is no single process for digital forensics. Refer to my dissertation for a list of proposed models.
Digital forensics is an investigation to answer questions. Consider a real world investigation that needs to answer who finished the pot of coffee without starting a new one. There is no single way to answer that question. One approach is to walk around with a thermometer to see who has the hottest cup of coffee, another is to dust for fingerprints, and another is to ask if there are witnesses. All could find the person while following different processes. Digital forensics is similar in that there is no single way to answer how a system was compromised or if it contains contraband.
Because there is no single process for digital or physical investigations, my research attention focused on identifying the fundamentals of a digital investigation. If there are many ways to answer the questions, then what do they have in common? One of the results of this work was the Computer History Model, which describes what occurred in a computer and can be used to model digital investigation techniques. The Computer History Model is unique with respect to the previously proposed process models because it is based on mathematical theory of computation models and is not simply an arbitrary grouping of steps and phases.
General History Model Concept
The general concept of the Computer History Model applies to both the physical and digital world. The concept in the physical world is that every object has a theoretical history that records what is sensed at a given time. Consider if at every second of your life, that a record was kept of what you were seeing, feeling, hearing, tasting, smelling, etc. Consider if your computer mouse also had a history of what was touching it at every second of its life.
If this theoretical history existed for every object and an investigator had access to them, then crimes would be easy to solve. The investigator would refer to a witness's history and observe what he saw. She would refer to the history of a murder weapon to identify who was touching it at the time of a murder. She would refer to the suspect's history to identify what he was doing during the time of the crime.
Unfortunately, complete histories are infrequent in reality. The main exception are devices that record video and audio (i.e. the seeing and hearing senses). Instead, investigators identify the people and objects that are potentially associated with a crime and try to learn as much as possible about the object's history. They try to identify who was touching a murder weapon or who left DNA behind at a crime scene. They try to put the pieces together using partial information about what came into contact.
Returning to our original coffee example. The investigators are looking for someone who observed the last cup of coffee being poured, for someone who was last touching the coffee pot, and for coffee that was the most likely to have been recently poured.
The last major point on the general concept is that histories exist at multiple levels. There is a history at the level we can see with our naked eye and there is a history at the microscopic and molecular levels. Investigators use the different levels of histories for different types of cases. For example, witnesses report visual-level details while DNA analysis reports much lower-level details.
Computer History Model
The Computer History Model is based on the concept that computers too have a history. The history contains the sequence of states and events between them. The state of a computer is the value of its storage devices, including memory and hard disks. If any bit in any storage location changes, then the system is in a new state. An event is an occurrence that changes the state. At the lowest level, an event occurs for every processor cycle. Processors, such as the Central Processing Unit (CPU), read data from a storage location, process the data, and write the result to a storage location. The CPU reads and writes data from memory and other processors read data to and from hard disks. Each time a processor writes data to a register, memory, or a hard disk then the system is in a new state.
Consider a computer with 1GHz CPU. This CPU executes 1 billion events per second and therefore there are potentially 1 billion state changes every second. The number of possible events that can occur at any time is based on the types of processors that are installed in the computer and the number of possible states is based on the amount of memory and storage that a computer has. For readers who have studied theory of computation, we are assuming a finite state machine (FSM).
The history of the computer is the sequence of states and events. The following figure is a graphical (and extremely over simplified) way to represent the history. The first state is on the left and an "Add" event reads two locations in memory and stores the result in another memory location. A state change has just occurred. The next event moves the value from memory to the hard disk. This process continues until the computer is powered off.
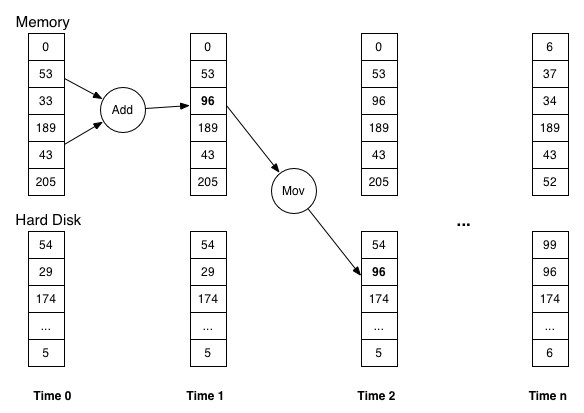
If you saved every state and event of the computer (i.e. it's history), then you could answer any digital investigation question about it. Unfortunately, a digital investigator will have only the current state of the system or the state when an acquisition was performed. Perhaps he will also have backups of the system, which represent the state of the system at a previous time. He must make inferences about the previous states of the system. For example, given the current state, he must make inferences about what events caused the system to get into that state. Did the file get there from application X or application Y? Was the file created intentionally by the user or was it automatically saved by the OS?
The Computer History Model occurs at multiple levels. The lowest is the primitive history and it contains processor-level events, bytes in memory, and hard disk sectors. The higher-level histories are called abstract histories, which contain abstract events and storage locations. An abstract event is a occurrence that causes one or more lower-level abstract or primitive events to occur. For example, clicking on the "Save" button is one event for the user, but it causes hundreds or thousands of primitive-level events to occur that will create a file in the file system and copy the data from memory to the file.
An abstract storage location is a virtual storage location that is made up of lower-level abstract and primitive storage locations . The most common example of an abstract storage location is a file. To the user, a file is a single storage location, but it is really the concatenation of hard disk sectors.
Abstract events and storage locations exist because of the programs that are installed on the computer. For example, WIndows does not natively support the Linux Ext3 file system. A file in an Ext3 file system cannot be read from or written to from within Windows unless special programs exist. Therefore, Ext3 files are not in the abstract state of a Windows system unless the special programs exist. The impact of this is that if you want to determine what abstract storage locations and events were possible at each time, you must enumerate all of the programs that were running at that time and determine their capabilities.
Most digital investigations occur at the abstract level. An investigator typically needs to answer questions about files and application-level events. If you want to read about the full definition of the model, which is defined using a finite state machine and lots of sets and functions, check out my dissertation.
Practical Impact
The Computer History Model is highly theoretical, but it does have some practical implications. I conclude this with some examples (there are more in the dissertation).
One impact of this model is to help phrase the questions that a digital investigation is trying to answer. Questions can be about abstract or primitive states or events at given times. For example, you could ask "do contraband files exist in the current state?", "given the acquired state, did file X exist in a previous state?", or "given the acquired state, when did application X create file Y?". You cannot answer questions like "what happened?" or "what is interesting in this disk image?" without making assumptions about what "interesting" means.
If we had the full history of the system, we would answer questions by simply finding the relevant states or events and answering the questions. For example, to determine if file X existed in a previous state, we would examine all previous states to determine if the file existed. Because we never have the full history, we must start with the current or acquired state of the system and reconstruct previous states. However, it is impossible to fully reconstruct the history of a system given only a single state. There are too many possibilities.
Because we cannot fully reconstruct previous states with any certainty, we end up making assumptions. We make assumptions about which programs were installed and what files existed at certain times. To be a scientific process though, we should be making hypotheses and testing them. We should be stating that we think program X was installed at time Y and test the statement by trying to prove that it was NOT installed. If we can find evidence that it was installed and we cannot show that it was not installed, then we can conclude with an amount of certainty that it was installed. However, digital forensics is not at that point yet because we have no objective way of calculating how confident we are in our conclusions. We cannot conclude that we are 80.25% confident that a file was created by a web browser (and not a backdoor trojan) because we do not data to support those types of calculations.
There are other impacts as well that will be outlined in other articles. These include the application of the forensic principles of transfer (Locard), identification, classification, individualization, association, and reconstruction. Another impact is on the classification of digital forensic tools.
Conclusion
This article is a very high-level introduction to the Computer History Model. The motivation for creating the model was to have a theoretical foundation for future work. The future work that this will impact includes the application of forensic principles, event reconstruction, and the calculation of certainty values.
Brian D. Carrier. A Hypothesis-Based Approach to Digital Forensic Investigations. Ph.D. Dissertation. Purdue University. 2006.